Çok uzun bir aradan sonra ilk yazımı yazıyorum. Bu arada birçok kez yazı yazmak istemiştim ama nasip olmadı.
Bilgiyi, yazı ile pekiştirin.
Düsturu ile umarım arkası gelir.
Yazıda big data nedir?, spark nedir? , hadoop nedir ? vs bahsetmeyeceğim. Bunlar zaten herkesin az çok bilgi sahibi olduğu benim ise çok az bilgi sahibi olduğum geliştirmeye çalıştığım alanlar. Bu konularla ilgili yeni şeyler öğrendikçe ve tecrübe ettikçe pekiştirmek ve paylaşmak adına buradan yazıyor olacağım..
Spark ile geliştirme yapmak için bir çok dil kullanılabiliyor. Bu dillerden biri de Python. Python geliştirme ortamı için de seçenekler oldukça fazla bunlardan benim tercih ettiğim ise PyCharm.
İlk Spark uygulamasını Windows ortamında geliştirmek için aşağıdaki adımları takip edebilirsiniz :
- Anaconda kurulumu
- Anaconda, python derken kral kobra !
- Anaconda, özellikle işi veri ile olanlar için matematik ve mühendislik ile ilgili gelişmiş paketler sunar. Daha detaylı bilgiye sayfasından ulaşabilirsiniz.
- Installer’ı olduğu için detaylandırmaya gerek yok https://www.continuum.io/downloads adresinden indirip kurulum yapılabilir.
- Spark kurulumu
- Kurulum oldukça basit, sadece indirmek yeterli 🙂
- http://spark.apache.org/downloads.html adresinden (şu anki sürüm: 1.6.1 ) kurulum yapabilirsiniz. Benim seçimim aşağıdaki:
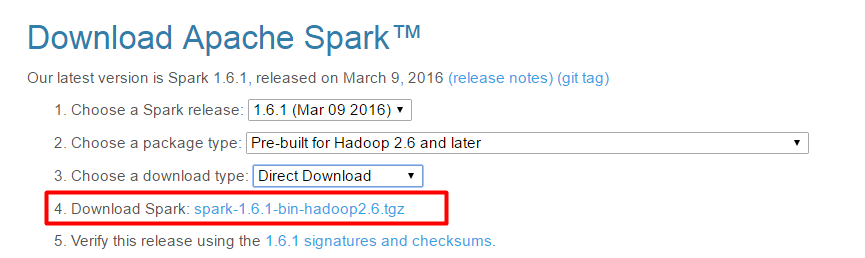
- Windows üzerinde geliştirme yaptığımız için winutils e gerek olacaktır.
- Aşağıda kaldığı için görünmüyor yukardaki ekran görüntüsünde fakat, sistem değişkenlerine ayrıca SPARK_HOME u da eklemeniz gerekecektir. Bu değişkenin değeri ise sizin Spark ın sayfasından indirdiğiniz arşivi çıkardığınız yer olmalıdır.

- Test edersek
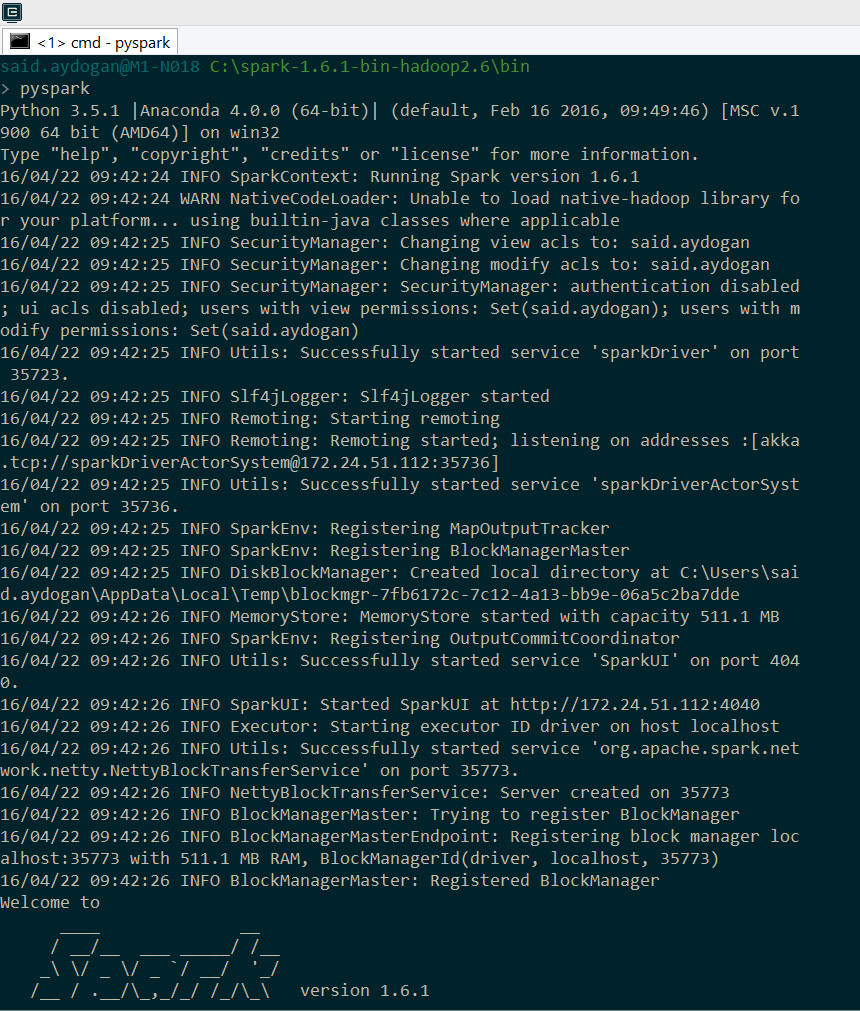
INFO mesajlarını kapatmak istiyorsanız. Spark dizini altında conf klasöründe log4j için template görebilirsiniz. INFO mesajlarını göstermeyip sadece WARN mesajlarını göstermesini isteyebilirsiniz. Conf içerisinde daha bir çok ayarlamalar yapmanızı sağlayacak templateler bulunuyor ayrıca incelenmesi gerekir.
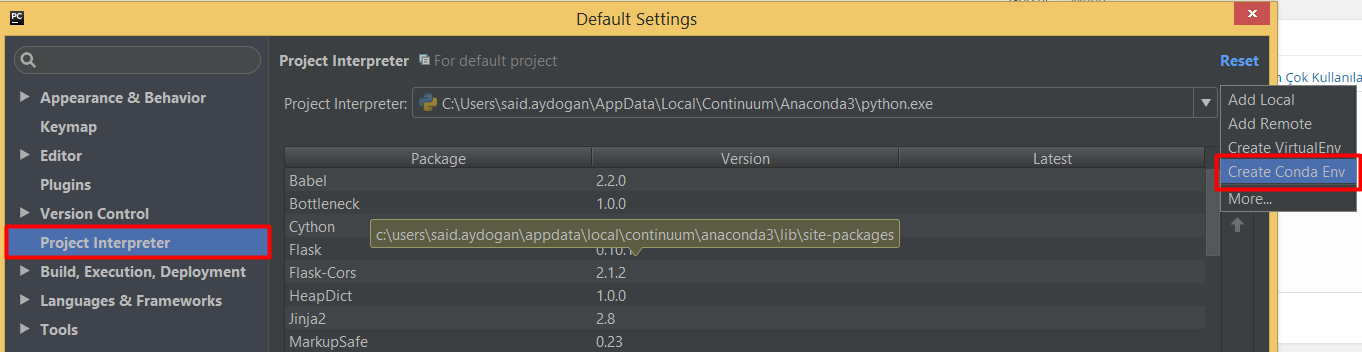
- PyCharm entegrasyonu

Settings ‘ e tıklanıp. Create Conda Environment seçilir.


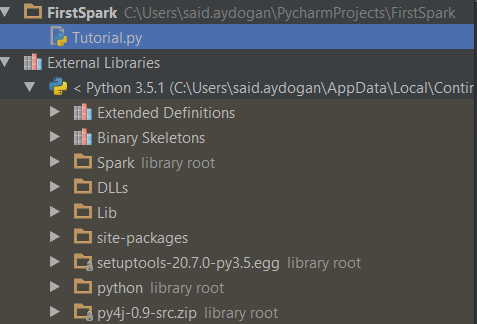
 Yukardaki işlemleri gerçekleştirdiğimizde ve PyCharm ile yeni bir python-spark projesi açtığımızda
Yukardaki işlemleri gerçekleştirdiğimizde ve PyCharm ile yeni bir python-spark projesi açtığımızda

|
|
from pyspark import SparkContext |
kodu derleyici için de anlamlı bir hal alacaktır.
- Test
|
|
from pyspark import SparkContext sc = SparkContext() data = [1, 2, 3, 4, 5] distData = sc.parallelize(data) print(distData.reduce(lambda a, b: a + b)) |
Dizinin elemanlarını toplayan yukarıdaki Python kodunu çalıştırdığımızda ekran görüntüsünün aşağıdaki gibi olduğunu görüyoruz.

PyCharm ve Spark kullanarak artık geliştirme yapmaya hazırız!
